FPGA ALU with Transaction Table Aggregation
Thursday, October 30, 2025
View ProjectPipelined ALU with Transaction Table Aggregation
Summary
This digital design project addresses a critical performance bottleneck in high-speed FPGA network acceleration: external memory latency. In 100 Gb/s monitoring systems, updating flow counters requires a Read-Modify-Write (RMW) sequence. Traditional pipelines frequently stall during these cycles, especially when multiple requests target the same address, leading to significant throughput degradation.
To solve this, I engineered a novel ALU architecture in SystemVerilog that utilizes a specialized Transaction Table to aggregate operations. By exploiting mathematical associativity rather than data locality, the system masks memory latency and maintains high throughput even under high-collision workloads.
Technical Implementation & Architecture
The core innovation is a local Transaction Table that intercepts and stores partial sums from multiple updates targeting the same memory address. This allows the ALU to accept new requests immediately without waiting for the slow external memory handshake to complete.
Key engineering highlights include:
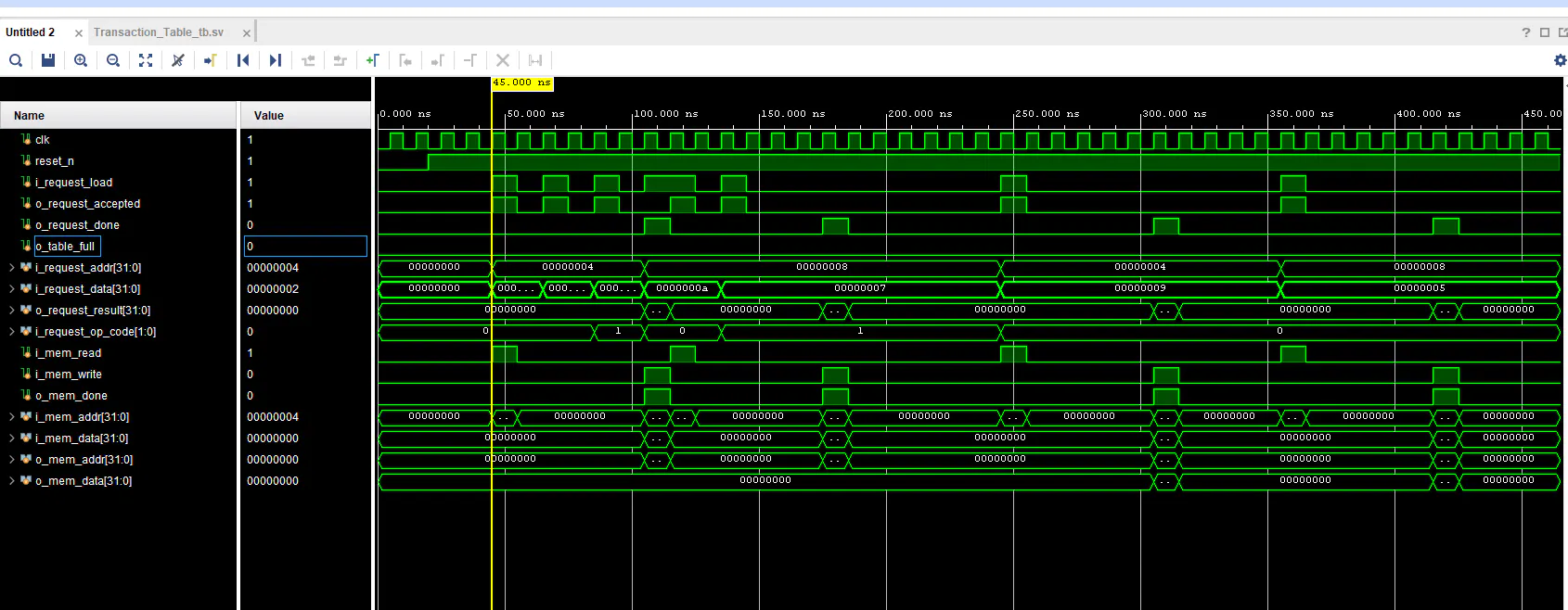
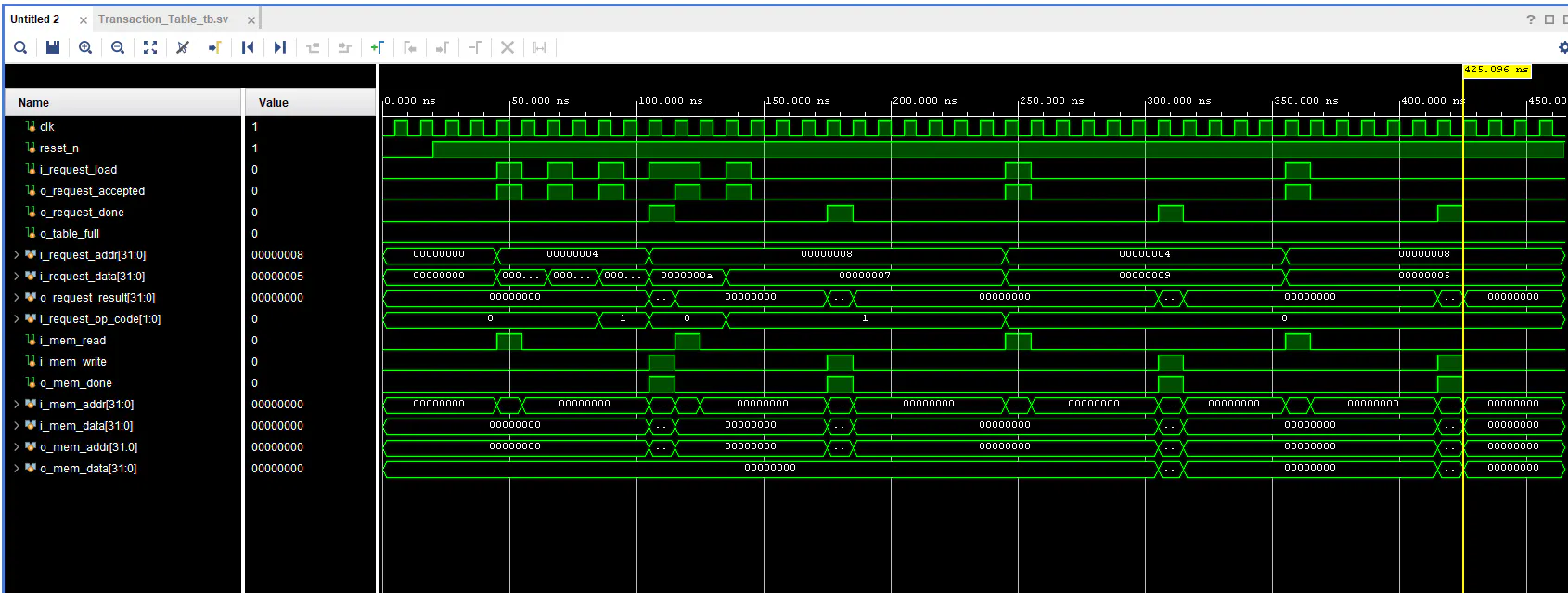
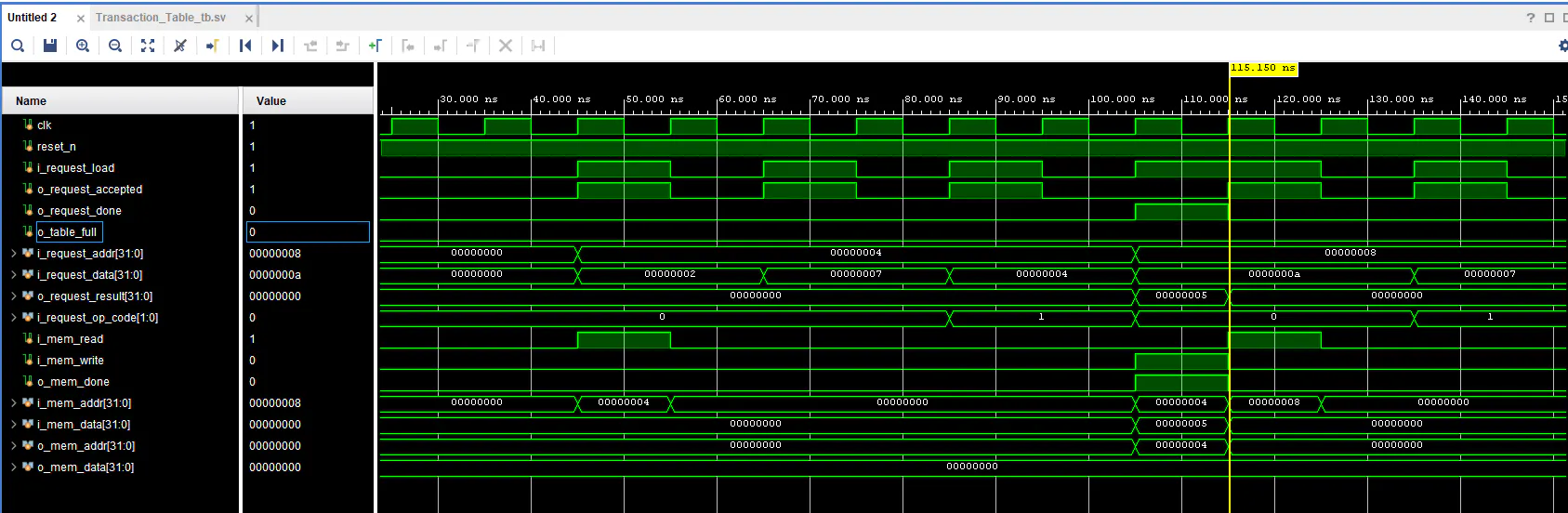
- Non-Blocking Logic: Engineered a state machine that detects address collisions and aggregates values locally (Mnew = Mold + SUM Un). If a request matches an active table entry, it is aggregated instantaneously, eliminating redundant RMW cycles.
- Associativity-Based Optimization: Unlike traditional caches that rely on spatial/temporal locality, this design uses associativity to resolve flow collisions—a more effective strategy for network traffic patterns.
- Simulation & Verification: Developed a comprehensive SystemVerilog simulation environment featuring a configurable Mock External Memory. This environment accurately simulates real-world latency and request/acknowledge handshake protocols to stress-test the aggregation logic.
Technologies I used for this project
Main Technologies
- SystemVerilog (HDL)
- RTL Design & Synthesis
- Digital Logic Design
Architecture Concepts
- Latency Mitigation
- Read-Modify-Write (RMW) Optimization
- Transaction Aggregation
- Non-Blocking I/O
Hardware & Tooling
- Digilent Nexys A7-100T (FPGA)
- AMD Vivado ML Edition
- Simulation Waveform Analysis
Results
Quantitative simulation results under a high-collision workload (6 consecutive operations targeting the same address) demonstrate a massive performance gain over standard pipelined architectures:
- Total Active Time: Reduced from 690 ns to 380 ns (44.93% reduction).
- Throughput Improvement: Achieved a 1.81x speedup factor (Sp), confirming the architecture's efficiency in resolving memory-bound bottlenecks.